Kubernetes pour les développeurs
Qu’est ce qu’une image ?
Dans le monde de Kubernetes, une image est une encapsulation d’une application (par exemple un microservice) sous une forme portable, facile à déployer. L’image contient tous les fichiers que l’application a besoin pour fonctionner correctement, et elle est construite à partir d’un mini-noyaux Linux.
Une fois lancée, une image devient un conteneur, donc un conteneur est une instance d’une image.
Il y a plusieurs façons de créer une image :
- via un fichier Dockerfile
- via d’autres outils comme Jib pour les developpeurs Java.
Voici un exemple d’un Dockerfile :
FROM nginx:alpine
MAINTAINER Gégé Rasolo
COPY index.html /usr/share/nginx/html/index.html
Une image un ensemble des couches et toujours construite à partir d’une autre image. Dans l’exemple ci-dessus, on part de l’image “nginx:alpine”, qui elle est basée sur une autre image “alpine” et ainsi de suite.
Si on souhaite construire une image à partir de zero, on utilise l’instruction “FROM scratch”, https://hub.docker.com/_/scratch une image vide qui permet de créer “from scratch”.
Par exemple, l’image busybox
FROM scratch
ADD busybox.tar.xz /
CMD ["sh"]
Jib, est un outil open-source, 100% en Java, developpé par Google, il permet de construire facilement une image sans avoir besoin d’un daemon comme Docker.
Qu’est ce qu’un conteneur ?
Un conteneur est une instance d’une image. Si on compate à la programmation orienté objet, image est un “Class”, un conteneur est un “object”.
Le conteneur peut fonctionner sur n’importe quel système compatible, sur n’importe quel Cloud, sans aucun changement.
Pour demarrer un conteneur, il faut un “runtime”, ce conteneur “runtime” permet à l’application (conteneur) de communiquer à la machine hôte et donc d’utiliser les resources necessaires (CPU, RAM, Disque, Reseaux).
Conteneur runtime : docker, lxc, runc, cri-o, rkt, containerd, podman, buildah.
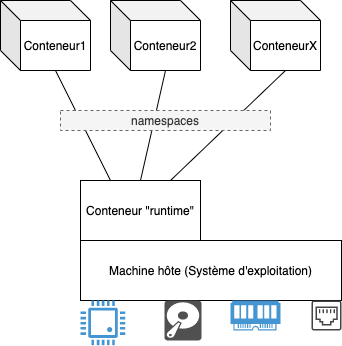
Un conteneur est fortement inspiré des fonctionnalités offertes par le systeme Linux.
Au sein du “runtime”, chaque conteneur est isolé par le concept de “namespaces”. Cette isolation s’applique sur le reseau (network), fichier (file), utilisateurs (users), processus (processes), et les communications inter-processus (IPCs).
L’utilisation d’un conteneur est standardisé et suit la specification d’OCI (Open Containers Initiative) https://opencontainers.org. Ce qui permet de deployer et executer n’importe quel conteneur sur n’impore quel “runtime”.
On peut télécharger une image depuis des plateformes comme https://hub.docker.com/, https://quay.io/, et bien d’autres.
L’exemple suivant nous montre comment on lance un conteneur à partir de l’image “nginx:1.19”. Sachant que j’utilise le “runtime” docker sur mon ordinateur, le “runtime” télécharge automatiquement l’image depuis la plateforme docker.io si l’image n’est pas disponible en local. C’est comme si on écrit (docker.io/nginx:1.19 à la place de nginx:1.19 seulement)
docker run --name mon-serveur-web -d nginx:1.19
Unable to find image 'nginx:1.19' locally
1.19: Pulling from library/nginx
75646c2fb410: Pull complete
6128033c842f: Pull complete
71a81b5270eb: Pull complete
b5fc821c48a1: Pull complete
da3f514a6428: Pull complete
3be359fed358: Pull complete
Digest: sha256:bae781e7f518e0fb02245140c97e6ddc9f5fcf6aecc043dd9d17e33aec81c832
Status: Downloaded newer image for nginx:1.19
99d68c4d2eb755d3c094084d46006c26bf6f32ebf133fe436b9fadc6739b7163
Et pour vérifier que notre serveur web Nginx est maintenant lancé :
docker ps
99d68c4d2eb7 nginx:1.19 "/docker-entrypoint.…" 30 seconds ago Up 29 seconds 80/tcp mon-serveur-web
Kubernetes
Un systeme d’information contient majoritairement beaucoup d’applications, et donc beaucoup de conteneurs à deployer, ça peut être deployée sur une seule grosse machine (pas vraiment une bonne idée), ça peut être sur plusieures machines en mode cluster ou sur le cloud.
Plusieurs solutions sont possible mais nous nous interessons sur Kubernetes qui est devenu, de facto, le systeme d’orchestration des conteneurs.
Mais à titre d’information, on peut utiliser :
- Docker compose permet de déployer plusieurs conteneurs sur une seule machine en une seule commande, encore fois, n’est une bonne idée pour la production.
- Docker swarm on peut dire que c’est le concurrent de Kubernetes, simple à mettre en place.
Developpée par Google, rendu public en 2014 et premier release en 2015 et maintenant appartient à la fondation Linux. Kubernetes est developpé en GoLang.
https://research.google/pubs/pub43438/
Comme les projets Linux, il y a beaucoup de distribution de Kubernetes, on peut utiliser la distribution originale “Kubernetes Vanilla”, gérée par la communauté, mais on peut aussi choisir d’autres distributions comme OpenShift de chez RedHat etc… https://kubernetes.io/fr/docs/setup/pick-right-solution/
Si on simplifie, Kubernetes est un RESTful API qui expose toutes les operations possibles à faire sur sa base de données, qui est une base de données NoSQL ETCD.
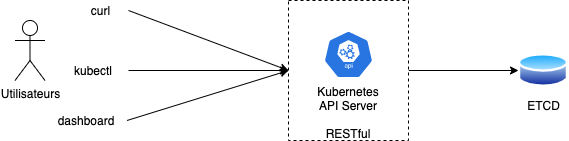
dashbord
Kubernetes IDE comme Lens
kubectl
L’outil pour administrer Kubernetes, kubectl est basé sur curl.
https://kubernetes.io/docs/reference/kubectl/cheatsheet/ https://kubectl.docs.kubernetes.io/
curl
kubectl proxy --port=8001 &
curl http://localhost:8001
curl http://localhost:8001/api/v1/namespaces/default/pods
Architecture de Kubernetes
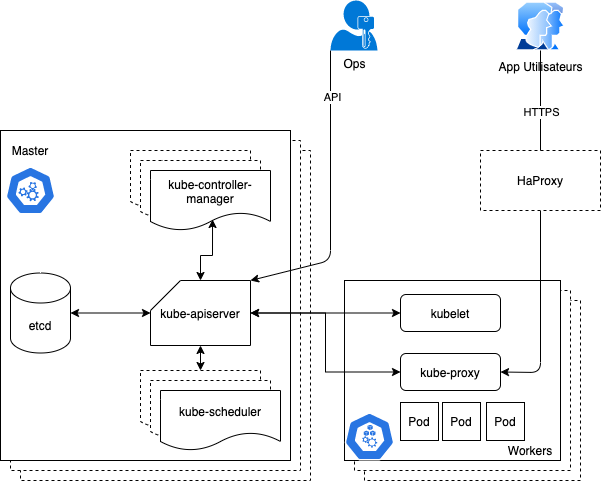
L’API (kube-apiserver)
Toutes les fonctionnalités de Kubernetes sont accessible via API RESTful.
Plusieurs API-Resources : apps, networking, storage, …
Tous les 3 mois il y a un update d’API, il faut bien identifier la version à utiliser.
Pour savoir la version de l’API utilisée par le cluster, il suffit de lancer la commande suivante :
kubectl api-versions
L’orchestrateur (kube-scheduler)
//TODO
Le Controlleur (kube-controller-manager)
On peut resumer son rôle avec le bout de code ci-dessous :
for {
desired := getDesiredState()
current := getCurrentState()
makeChanges(desired, current)
}
L’agent (kubelet)
L’agent de Kubernetes qui se trouvent sur chaque noeuds du clusteur. Cet agent qui recoit et execute les ordres venant de l’orchestrateur. Il remonte aussi toutes les informations au master via l’API et ces informations sont stockées dans la base de données ETCD.
kubeproxy
//TODO
ETCD
//TODO
Deployer un mini-cluster Kubernetes pour le developpement
Plusieurs solutions sont disponibles :
- DockerDesktop : simple et facile à mettre en place pour Windows et MacOS.
- Minikube pour Linux, macOS et windows.
Personnellement, je travaille sur DockerDesktop pour macOS
Quelques commandes pour tester notre cluster
kubectl version
Client Version: version.Info{Major:"1", Minor:"19", GitVersion:"v1.19.7", GitCommit:"1dd5338295409edcfff11505e7bb246f0d325d15", GitTreeState:"clean", BuildDate:"2021-01-13T13:23:52Z", GoVersion:"go1.15.5", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"19", GitVersion:"v1.19.7", GitCommit:"1dd5338295409edcfff11505e7bb246f0d325d15", GitTreeState:"clean", BuildDate:"2021-01-13T13:15:20Z", GoVersion:"go1.15.5", Compiler:"gc", Platform:"linux/amd64"}
Deployer et lancer rapidement un pod (methode imperative)
kubectl run monnginx --image=nginx
pod/monnginx created
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/monnginx 1/1 Running 0 3m26s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 37m
Les principaux objets utilisés par Kubernetes
Pods
Est une abstration d’un serveur. Un pod peut contenir plusieurs conteneurs dans un seul namespace et ils sont exposé via une seule adresse IP.
En production, un pod ne doit pas être demarré tout seul, il ne sera pas redeployer quand le noeud s’arrete. Un pod peut être créé à partir d’un deploiment, job ou cronjob.
apiVersion: v1
kind: Pod
metadata:
name: monnginx
namespace: default
spec:
containers:
- name: monnginx
image: nginx:latest
kubectl explain pods
kubectl explain pods.spec
Generalement, un pod contient un seul conteneur mais, dans certains cas on a besoin de lancer multiples conteneurs dans un pod:
- init container : pour initialiser une configuration par exemple
- sidecar container : produire des fonctionnalités supplementaires au conteneur principal, par exemple gestion des logs, synchronisation, metriques, tracing
- ambassador container
- adapter container
InitContainers
apiVersion: v1
kind: Pod
metadata:
name: initcontainer-example
spec:
initContainers:
- name: sleepy
image: alpine
command: ['sleep', '20']
containers:
- name: web
image: nginx
Comment investiguer un probleme dans un pod ?
kubectl describe pod podname
Lit le status courant du pod dans la base de données etcd.
kubectl logs podname
Lit le contenu stdout du pod, s’il y a plusieurs conteneurs il faut ajouter l’option -c avec le nom du conteneur
kubectl exec (executer une commande dans un conteneur, s’il y a plusieurs conteneurs il faut ajouter l’option -c)
kubectl get pods –all-namespaces -o wide
securityContext d’un pod
apiVersion: v1
kind: Pod
metadata:
name: nginxsecure
spec:
securityContext:
runAsNonRoot: true
containers:
- image: nginx
name: nginxTester l’accessibilité d’un pod
kubectl port-forward pod/podname port_externe:port_interne
Limitation des resources utilisé par un pod
Par defaut un pod utilise autant de CPU et memoire pour faire son travail. On peut controler l’utilisation des resources via pod.spec.containers.resources.
CPU : millicore (m), 1000m est l’equivalent d’un 1 CPU.
requests:
limits:
Deployments
Une entité pour standardiser la gestion des pods. Un deployment crée un autre object “replicaset” automatiquement, le “replicaset” est fortement lié à un “deployment” et donc inutile de le gerer separement.
Un deploiement permet de gerer le scalabilité de l’application, la strategie de mise à jour et l’historique.
Si un pod tombe en panne, le deploiement crée automatique un autre.
En production, il faut toujours créer un pod à partir d’un objet “deployment”.
Voici la structure d’un fichier YAML “deployment” :
apiVersion: apps/v1
kind: Deployment
metadata:
name: <NomApplication>
spec:
selector:
matchLabels:
app: <NomApplication>
template:
metadata:
labels:
app: <NomApplication>
spec:
containers:
- name: <NomApplication>
image: <Image>
resources:
limits:
memory: <Memory>
cpu: <CPU>
ports:
- containerPort: <Port>Comme tous les fichiers de Kubernetes, ça commence toujours par la version de l’API (apiVersion). L’objet de deploiement se trouve donc dans “apps”. “kind” sera toujours “Deployment”. metadata.name : est le nom de l’application à deployer. containers.image : est le chemin où se trouve l’image, et la version.
Voici un exemple complet pour deployer l’application Redis.
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
spec:
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
containers:
- name: redis
image: redis:alpine
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 6379❯ kubectl apply -f redis-deploy.yaml
deployment.apps/redis created
Verifions si l’application est demarrée.
❯ kubectl get po -l app=redis
NAME READY STATUS RESTARTS AGE
redis-d8c6dcd54-726rp 1/1 Running 0 24s
Ici, l’option “-l” veut dire label, et donc on souhaite juste afficher les pods qui ont un label “app” avec la valeur “redis”. C’est la valeur qu’on a indiqué dans le fichier YAML ci-dessus (spec.template.metadata.labels).
Et maintenant si supprime le pod :
❯ kubectl delete po redis-d8c6dcd54-726rp
pod "redis-d8c6dcd54-726rp" deleted
On constate que Kubernetes crée automatiquement une autre instance :
redis-d8c6dcd54-726rp 1/1 Terminating 0 66s redis-d8c6dcd54-xbx8j 0/1 ContainerCreating 0 3s
❯ kubectl get po -l app=redis
NAME READY STATUS RESTARTS AGE
redis-d8c6dcd54-xbx8j 1/1 Running 0 86s
On a dit que l’historique de deploiement est aussi gérée par l’object “Deployment”. On peut consulter cette historique via la commande :
❯ kubectl rollout history deployment redis
ça devrait afficher le resultat suivant :
deployment.apps/redis
REVISION CHANGE-CAUSE
1 <none>
Ici on n’a qu’une seule revision parce qu’on a rien modifié pour l’instant. Kubernetes suit une strategie quand une modification est faite sur le deploiment :
- la stratégie “Recreate” : ça supprime l’ancien pod et crée une nouvelle, ça implique une petite indisponibilité du service.
- la stratégie “RollingUpdate” : cette stretégie garantit la disponibilité de l’application, et donc Kubernetes remplace un pod à la fois.
On va apporter quelques modifications à notre fichier redis-deploy.yaml pour gérer la stratégie de mise à jour et commençons par une ancienne version de Redis “5.0.12-alpine” :
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
spec:
replicas: 4
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 2
maxUnavailable: 1
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
containers:
- name: redis
image: redis:5.0.12-alpine
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 6379❯ kubectl apply -f redis-deploy.yaml
deployment.apps/redis configured
Verifions :
❯ kubectl get po -l app=redis
NAME READY STATUS RESTARTS AGE
redis-d8c6dcd54-9bqfl 1/1 Running 0 12s
redis-d8c6dcd54-bjxjf 1/1 Running 0 12s
redis-d8c6dcd54-nnrqs 1/1 Running 0 12s
redis-d8c6dcd54-t8t26 1/1 Running 0 12s
Maintenant on a bien 4 replicas, comme c’est demandé dans le fichier YAML.
❯ kubectl rollout history deployment redis
deployment.apps/redis
REVISION CHANGE-CAUSE
1 <none>
Maintenant, modifions la version de Redis :
❯ kubectl set image deployment.apps/redis redis=redis:6-alpine
deployment.apps/redis image updated
Vérifions si la version a été mise à jour
❯ kubectl get deployment.apps/redis -o=jsonpath='{$.spec.template.spec.containers[:1].image}'
redis:6-alpine
Et si on reconsulte l’historique, la revision devrait être 2 :
❯ kubectl rollout history deployment redis
deployment.apps/redis
REVISION CHANGE-CAUSE
1 <none>
2 <none>
kubectl rollout history deployment redis --revision=1
deployment.apps/redis with revision #1
Pod Template:
Labels: app=redis
pod-template-hash=68d544cd59
Containers:
redis:
Image: redis:5.0.12-alpine
Port: 6379/TCP
Host Port: 0/TCP
Limits:
cpu: 500m
memory: 128Mi
Environment: <none>
Mounts: <none>
Volumes: <none
kubectl rollout history deployment redis --revision=2
deployment.apps/redis with revision #2
Pod Template:
Labels: app=redis
pod-template-hash=5f7d7d959f
Containers:
redis:
Image: redis:6-alpine
Port: 6379/TCP
Host Port: 0/TCP
Limits:
cpu: 500m
memory: 128Mi
Environment: <none>
Mounts: <none>
Volumes: <none>
❯ kubectl get replicasets.apps -l app=redis
NAME DESIRED CURRENT READY AGE
redis-5f7d7d959f 4 4 4 11m
redis-68d544cd59 0 0 0 15m
Si on revient en arriere
❯ kubectl rollout undo deployment redis --to-revision=1
deployment.apps/redis rolled back
Services
Un pod tout seul n’est pas accessible depuis l’exterieur en tant qu’application.
Pour debugger, on peut quand meme utiliser le “port forward”, mais ceci n’est pas l’utilisation normale d’une application.
kubectl port-forward pod/mynginx 8989:80
Forwarding from 127.0.0.1:8989 -> 80
Forwarding from [::1]:8989 -> 80
Handling connection for 8989

Pour exposer l’application, il faut créer un service.
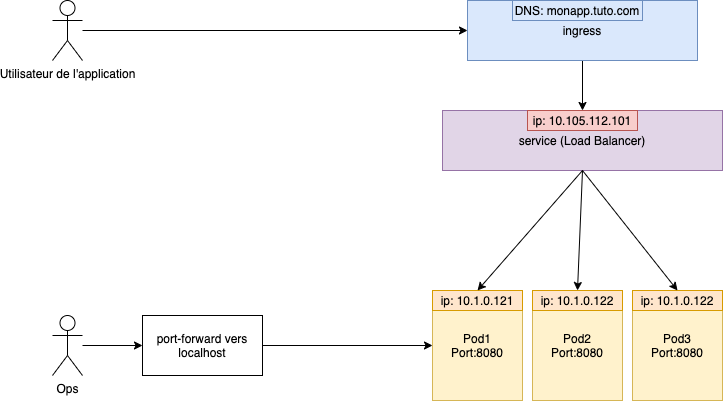
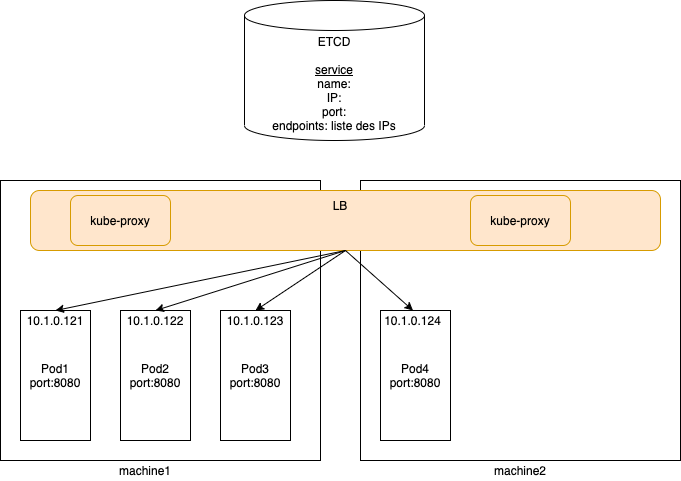
Il y a plusieurs type de service :
- ClusterIP : le type par défaut, et il est accessible qu’à l’interieur du cluster.
- NodePort : ouvre le port de l’application sur le noeud, et donc on peut y acceder directement depuis l’exterieur.
- LoadBalancer : utilisé par le fourniseur cloud public.
- ExternalName : une sorte de redirection de nom DNS.
- Service sans “selector” : utilisé pour connecter directement à une IP/port par exemple un serveur de base de données ou une application exterieur au cluster Kubernetes.
Pour exposer un service rapidement via la ligne de commande
kubectl expose deployment monnginx --port=80 --type=NodePort
service/monnginx exposed
kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4d1h
monnginx NodePort 10.102.160.117 <none> 80:32392/TCP 58s
Mais créer un service via la ligne de commande n’est pas vraiment la bonne pratique, il faut plutôt utiliser des fichiers. Voici un exemple de fichier YAML pour créer un service :
apiVersion: v1
kind: Service
metadata:
name: mon-serveur-web
spec:
selector:
app: monnginx
ports:
- port: 80
name: mon-serveur-web
type: NodePort
❯ kubectl apply -f nginx-service.yaml
service/mon-serveur-web created
Ingress
//TODO
Persistent Volumes
//TODO
Jobs
Pour executer une tache pendant un certain temps defini.
3 differentes type de jobs :
- non-parallel jobs : completions=1 parallelism=1
- Parallel jobs : completions=n, parallelism=m
- Parallel jobs avec un queue : completions=1, parallelism=n
Cronjobs
Namespace
Pour isoler les ressources dans le cluster. Par défaut, Kubernetes crée plusieurs namespaces : default, kube-node-lease, kube-public, kube-system.
Pour créer un namespace :
kubectl create ns ci-env
Pour lancer une requete d’un namespace, on utilise l’option “-n”
kubectl -n namespace get pods
Lister tous les namespaces
kubectl get ns
kubectl get pods --all-namespaces
Autorisation et permission
kubectl auth can-i get pods
kubectl auth can-i get pods --as toto@test.com
Comment on developpe pour Kubernetes ?
Build l’application -> La conteneuriser -> La deployer et executer sur K8S
developpement continue avec Skaffold
https://skaffold.dev/
Operator
un moyen d’etendre les ressources que l’API Serveur de Kubernetes peut gerer. On appelle ceci CRD (Custom Resource Definitions).